容错码是:“容易”编错,但“容许”编错的码。容错码的设置,是为了照顾不同的取码习惯,使他们用容易编错的码,照样可以打出所要的字来。
“容错码”主要有三种类型: 编码容错、字型容错、定义后缀。
王码五笔中的容错码设计了将近1000个左右,但实事上由于容错码打破了编码的唯一性,使人难以辨认正确的编码,是最终提高速度的障碍,所以很多五笔软件的码表中都去掉了容错码,只保留正确的、唯一的编码。
一、编码容错
个别汉字的书写笔顺因人而异,致使字根的拆分序列也不尽相同,因而容易弄错。如“长”和“秉”都有多种笔顺:

二、字型容错
个别汉字的字型分类不易确定,如:

三、定义后缀
为了进一步减少甚至杜绝重码,人为地将一些重码字的最后1个码或2个码修改为L(24),或改为有识别能力的字根的做法,叫“定义后缀”。
例如:“喜”与“嘉”重码,输入码都是FKUK。因为“喜”更常用,输入后显示在提示行的第一位,可以默认上屏,相当于不重码,等于“独享”原来的编码FKUK;为了使“嘉”在保留原来编码的同时,也能够“一步到位”上屏,就将最后一码K改为L,使“嘉”也可“独享”一个编码FKUL,这样输入FKUL就只出来“嘉”一个字了。
为什么要改为L而不用别的键呢?是因为以L为最后一码的编码空间冗余太大,又因为L键用右手无名指击键灵活方便。
这些常见重码字的“人工修正码”请见下表:
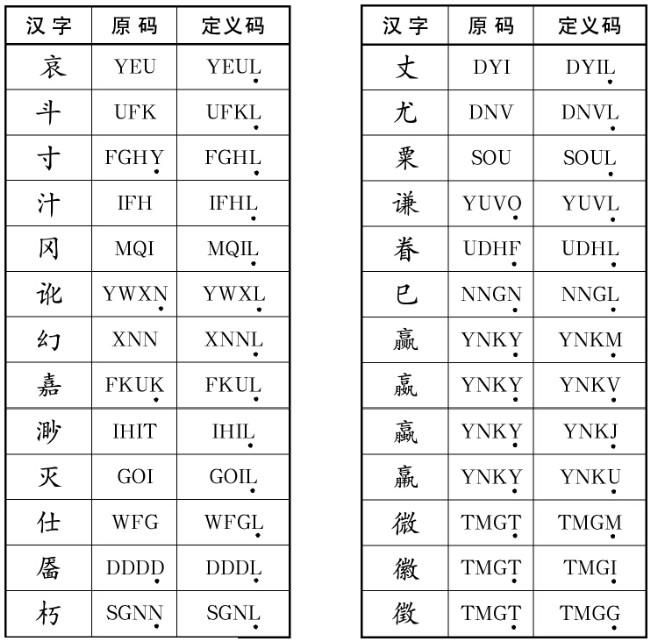
注:字母下边加圆点“.”者为补加或被修改的编码。